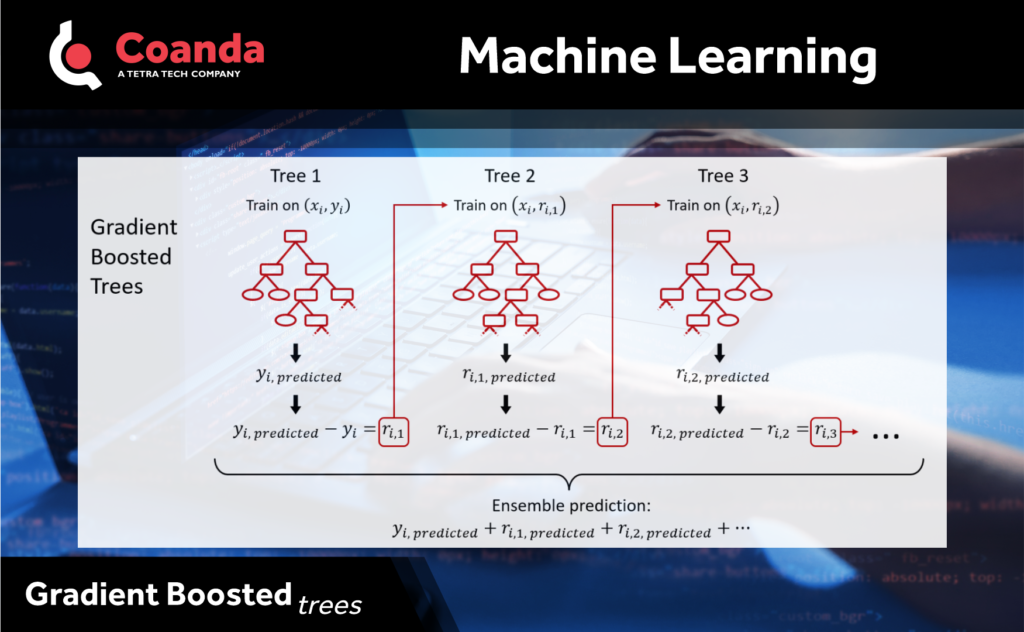
Gradient Boosted Trees
Posted on October 20, 2022 Big Data Machine Learning & AI

In addition to random forests, another popular tree-based ensemble model is Gradient Boosted Trees. The idea behind gradient boosting is to use an ensemble of weak learners where each learner tries to correct the errors made by the previous learners. In the case of gradient boosted trees, the weak learners are decision trees. The first tree is trained on the data and the second tree is trained on the residual error of the first tree and so on until a predetermined maximum number of trees has been reached. The advantage of boosted trees is that each tree can correct its predecessors making the ensemble of trees a better classifier than any single tree.
Gradient boosting on its own can lead to overfitting, so a variety of regularization methods are incorporated into the model. These include constraints and penalties on model complexity, “shrinkage” of the overall contribution of subsequent trees, and inclusion of stochasticity.
Gradient boosted trees typically performed better than random forests, and for tabular data they often result in the state-of-the-art performance. Both random forests and gradient boosted trees are models in our “toolbox” that we can bring out and apply when appropriate.
With that said, however, there is no one model that will perform best at every problem, so forethought and experience can help narrow down which models are better suited for a given problem. For example, tree-based models including random forests and gradient boosted tree typically result in non-smooth and discontinuous decision boundaries or response surfaces. With many physical processes we might expect continuous and smooth behaviors. So, depending on what is being modelled, a model that enforces smoothness (such as a Gaussian process regression model) could in some cases be better suited.