Imbalanced Data
Posted on November 22, 2022 Big Data Machine Learning & AI

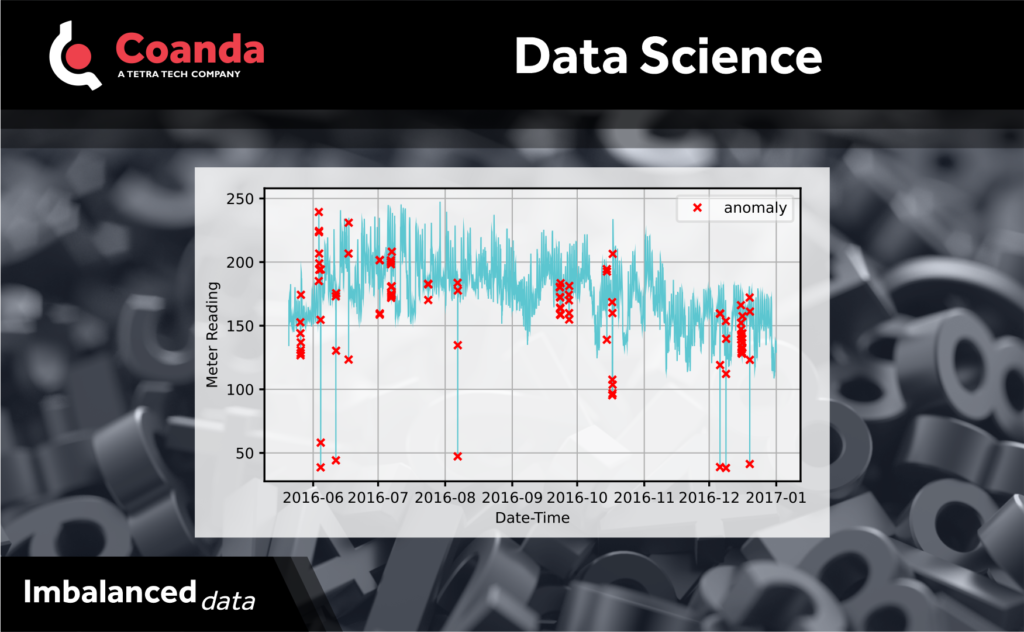
Data analysis can often involve the equivalent of looking for a needle in a haystack – identifying infrequent abnormal events or cases in data that is largely “normal”. This is a common problem in anomaly detection, e.g., equipment monitoring or for energy consumption (as shown in the image with anomalies in red). A challenge in this sort of analysis is that the training data is often imbalanced, i.e., there are only a few abnormal points of interest among a large amount of normal data. This makes it difficult to train a model to identify anomalous cases, and the use of the inappropriate metrics can make models look more accurate than they truly are.
A model that identifies all data as “normal” may appear very accurate in that it classifies most of the data correctly, even though it completely misses the cases of interest. For anomaly detection, metrics reflecting both the true and false detection rates of anomalies, e.g., the F1 score or area under the ROC curve, are more appropriate than simply using accuracy.
If there is enough training data, it can be undersampled by discarding some of the normal data to produce a balanced set. Alternatively, anomalous data can be oversampled by adding duplicates. This can also be achieved with data augmentation methods such as SMOTE (synthetic minority oversampling technique), which constructs artificial anomalous data points. The weight of the anomalous data in the training loss function can also be adjusted to balance the data, introducing a bias in model training for greater sensitivity to cases of interest.
Ensemble classifiers with bagging or boosting methods are also used for imbalanced data. In an ensemble classifier, the results from multiple classifiers are aggregated to produce an improved final result. Bagging (bootstrap aggregation) involves training each of the initial classifiers with different undersampled sets of training data. In boosting methods, a series of initial classifiers is trained, and then additional classifiers are added where more weight is placed on cases the initial classifiers got wrong.