Data Science – Model Cross-Validation
Posted on February 21, 2023 Big Data Machine Learning & AI

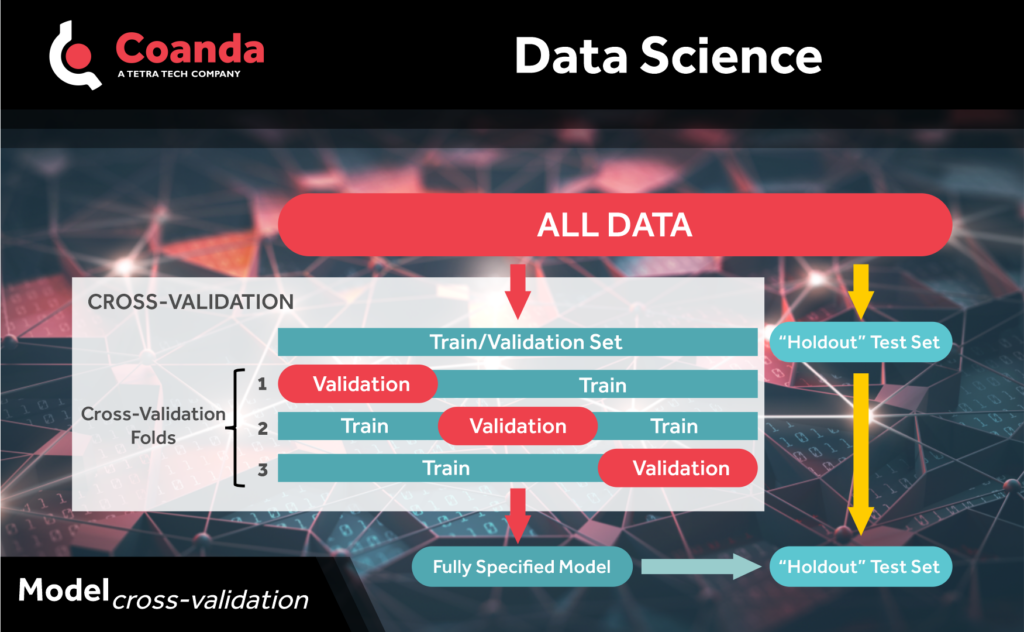
When modeling data, it is important to validate the model and to understand how accurate the model predictions are expected to be. One way to do this is with cross-validation. Cross-validation is a resampling method that can be used to assess how well a model will generalize to a “new” (i.e., independent) set of data. One round of cross-validation involves taking the data set with which you are going to train/fit your model and splitting this into two smaller sets. The first subset is used to train the model and the second is used to validate or test the trained model. This process is repeated by resampling from the original data to obtain multiple train-validate subsets and corresponding outcomes. The results from the cross-validation provide information that is useful for things like estimating model performance and model selection.
Some of the reasons to use cross-validation are the following:
-It can be used to estimate model accuracy and also the variance of the accuracy. The latter is important if you want to decide if one model is better than another model.
-It helps identify and prevent overfitting of models.
-It avoids data leakage when evaluating model performance and results in unbiased estimates of the model performance.
-If you leave a separate “holdout” test set of data right at the outset, cross-validation can be used for tuning model hyperparameters and for model selection.
One of the more popular cross-validation methods is called k-fold cross-validation where the training and validation data set is split into k equally sized subsets. Then each combination of k-1 subsets is used to train the model and the remaining set is used to validate the model, giving k rounds of cross-validation.