Categorical Variables
Posted on March 28, 2024 Mathematical Modeling

Categorical variables play an important role in many different data sets. Most machine learning modelling algorithms, however, require numerical inputs, so we must find a way to “encode” the different categories. Generally speaking, categorical variables can be either:
- Ordinal data: which is data that has a distinct order (e.g., level of education)
- Nominal data: which does not have any intrinsic ordering or hierarchy (e.g., type of additive)
There are a variety of different ways to handle categorical variables, each with its own advantages and disadvantages. Some of the more common ones are:
- Label encoding – assigns a unique integer to each category. This method is a simple (and obvious) choice for ordinal categorical variables where the order matters. This not suitable for nominal variables, however, as it introduces a false ordering of the categories and may mislead a model into learning incorrect relationships.
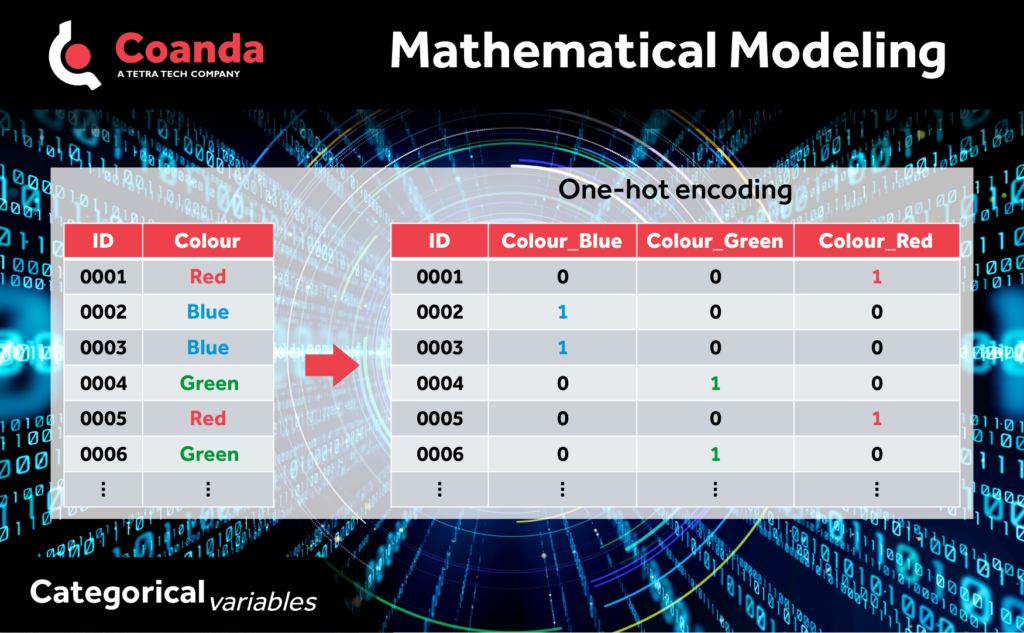
- One-hot encoding – converts each categorical value into a binary vector where each element represents the presence or absence of a particular category. One-hot encoding is straightforward and easy to implement, but it can lead to high-dimensional feature spaces, especially with variables containing many unique categories (high cardinality), which may introduce sparsity and increase computational complexity.
- Target Encoding – replaces categorical values with the mean of the target variable for each category. This method can capture the relationship between the categorical variable and the target variable, but it is prone to overfitting, especially with small or imbalanced datasets.
Choosing the appropriate method depends on various factors such as the nature of the categorical variables, the size of the dataset, the complexity of the model, and the desired interpretability and performance of the model. In a future post we will take a closer look at target encoding and its advantages and disadvantages.